
.png?width=603&height=259&name=Add%20a%20heading%20(3).png "Add a heading (3)")

SLO Use Cases
![]() SLOs offer key features and use cases in software engineering and service management. They enable teams to set error budgets, balancing innovation and stability while also providing a framework for managing technical debt effectively. SLOs foster collaboration, accountability, and continuous improvement, driving enhanced system performance and the delivery of high-quality services.
SLOs offer key features and use cases in software engineering and service management. They enable teams to set error budgets, balancing innovation and stability while also providing a framework for managing technical debt effectively. SLOs foster collaboration, accountability, and continuous improvement, driving enhanced system performance and the delivery of high-quality services.
Stop using complex specs and processes to create Prometheus based SLOs. Fast, easy and reliable Prometheus SLO generator.
Sloth generates understandable, uniform and reliable Prometheus SLOs for any kind of service. Using a simple SLO spec that results in multiple metrics and multi window multi burn alerts.

Making SLOs with Prometheus manageable, accessible, and easy to use for everyone!




- video

- article

- article
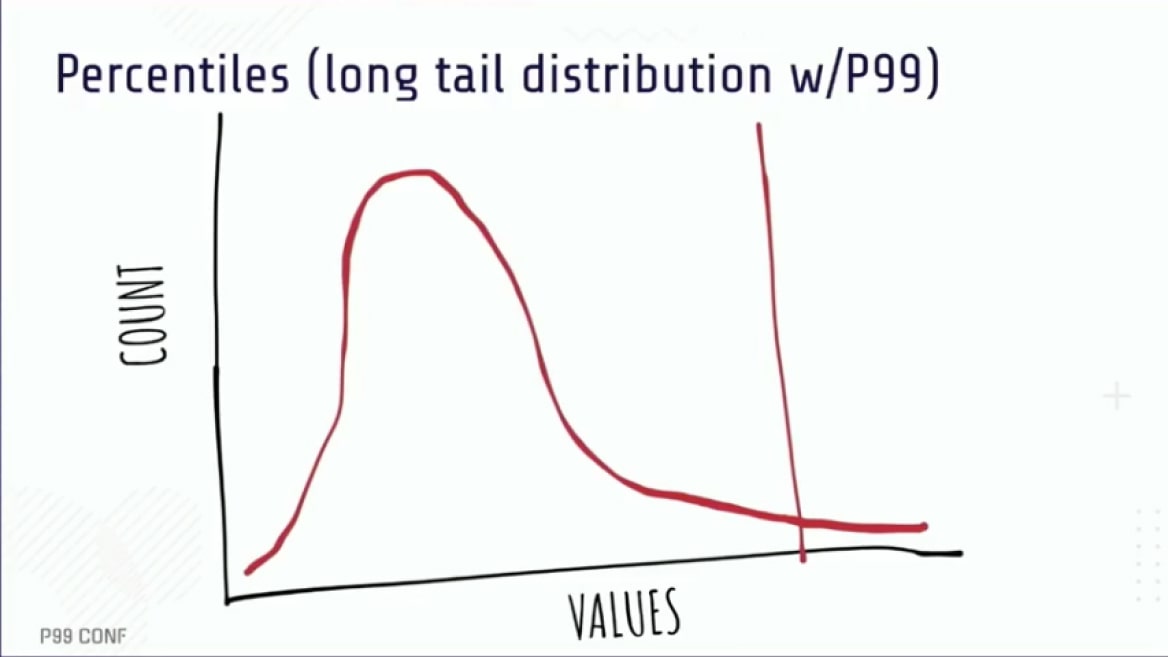
- article

- article
- video

- article
- video

- article

- article









-01.jpg?width=2000&name=The_State_of_Service_Level_Objectives_2022%20(1)-01.jpg)





